Introduction
At a key level, machine vision frameworks depend on advanced sensors secured inside mechanical cameras with particular optics to gain pictures. Those pictures are then bolstered to a PC so specific programming can process, examine, and measure different qualities for basic leadership.
These frameworks are unbending and slender in their application inside a manufacturing plant with robotization condition. Customary machine vision frameworks perform dependably with reliable, well-fabricated parts. They work by means of bit by bit separating and decides based calculations that are more practical than human examination.
On a creation line, a principles based machine vision framework can examine hundreds, or even thousands, of parts every moment. However, the yield of that visual information is still dependent on an automatic, rules-based way to deal with taking care of examination issues, which makes machine vision useful for:
Direction
Locate the position and direction of a section, contrast it with a predefined resilience, and guarantee it’s at the right edge to confirm legitimate gathering. Can be utilized for finding key highlights on a section for other machine vision apparatuses.
Recognizable proof
Read standardized identifications (1D), information network codes (2D), direct part checks (DPM), and characters imprinted on parts, names, and bundles. Additionally recognize things dependent on shading, shape, or size.
Checking
Calculate the separations between at least two focuses or geometrical areas on an item and decides if these estimations meet particulars.
Investigation
Find imperfections or different abnormalities in items, for example, marks effectively followed on or the nearness of wellbeing seals, tops, and so forth.
Deep learning utilizes a model based methodology rather than a standard based way to deal with settle for certain manufacturing plant mechanization challenges. By utilizing neural systems to train a PC what a decent picture depends on a lot of named models, deep learning will have the option to investigate deserts, find and group articles, and read printed markings, for instance.
Numerous terms are presently being utilized to depict what is, by a few, being advanced as an upheaval in machine vision, to be specific the capacity for frameworks to examine and arrange objects without the requirement for PC programming. Man-made brainpower (AI) and deep learning are only two phrasings used to advance such ideas.
Underneath this overstatement, in any case, depicting the fundamental science behind such ideas is increasingly straightforward. In conventional machine vision frameworks, for instance, it might be vital to read a standardized tag on a section, judge its measurements, or investigate it for blemishes.
To do as such, frameworks integrators regularly use off-the-rack software that offers standard apparatuses that can be sent to decide an information lattice code, for instance, or caliper devices set utilizing graphical UIs to measure part measurements.
Accordingly, the estimation of parts can be named positive or negative, contingent upon whether they fit some pre-decided criteria. In contrast to such estimation strategies, supposed “deep learning” apparatuses are better ordered as picture classifiers. Not at all like programming that explicitly peruses standardized identification information, they are intended to decide if an article in a picture is available or not.
Deep Learning Methods and Developments
1.Convolutional Neural Networks
Convolutional Neural Networks (CNNs) were motivated by the visual framework’s structure, and specifically the main computational models dependent on these nearby networks among neurons and on progressively composed changes of the picture are found in Neocognitron, which depicts that when neurons with similar parameters are applied on patches of the past layer at various areas, a type of translational invariance is obtained.
A CNN includes three fundamental kinds of neural layers, in particular, (I) convolutional layers, (ii) pooling layers, and (iii) completely associated layers. Each sort of layer assumes an alternate job. Each layer of a CNN changes the information volume to a yield volume of neuron actuation, in the long run prompting the last completely associated layers, bringing about a mapping of the info information to a 1D include vector.
i.Convolutional Layers
In the convolutional layers, a CNN uses different pieces to convolve the entire picture just as the middle of the road include maps, producing different element maps.
ii. Pooling Layers
Pooling layers are responsible for lessening the spatial measurements (width tallness) of the information volume for the following convolutional layer. The pooling layer doesn’t influence the profundity measurement of the volume. The activity performed by this layer is additionally called subsampling or down sampling, as the decrease of size prompts a concurrent loss of data.
In any case, such a misfortune is valuable for the system in light of the fact that the lessening in size prompts less computational overhead for the forthcoming layers of the system, and furthermore it neutralizes over fitting. Normal pooling and max pooling are the most regularly utilized systems.
iii. Fully Connected Layers
Following a few convolutional and pooling layers, the elevated level thinking in the neural system is performed through completely associated layers. Neurons in a completely associated layer have full associations with all enactment in the past layer, as their name suggests. Their enactment can thus be figured with a network increase pursued by a predisposition balance.
Completely associated layers in the end convert the 2D include maps into a 1D highlight vector. The determined vector either could be encouraged forward into a specific number of classes for order or could be considered as an element vector for additional handling.
The design of CNNs utilizes three solid thoughts: (a) neighbourhood responsive fields, (b) tied loads, and (c) spatial subsampling. In view of nearby responsive field, every unit in a convolutional layer gets contributions from a lot of neighbouring units having a place with the past layer. Along these lines neurons are fit for extricating basic visual highlights, for example, edges or corners.
These highlights are then joined by the resulting convolutional layers so as to recognize higher request highlights. Besides, the possibility that basic component identifiers, which are helpful on a piece of a picture, are probably going to be valuable over the whole picture is actualized by the idea of tied loads. The idea of tied loads limitations a lot of units to have indistinguishable loads. Solidly, the units of a convolutional layer are sorted out in planes.
All units of a plane offer a similar arrangement of loads. Along these lines, each plane is answerable for building a particular component. The yields of planes are called include maps. Each convolutional layer comprises of a few planes, with the goal that various element maps can be built at every area.
2. Classy administrators
Neural system based instruments are regularly used to decide part nearness or whether an item in a picture is fortunate or unfortunate. These apparatuses have a place with a gathering of calculations known as picture classifiers, running from case based classifiers, for example, k-closest neighbour (k-NN) to choice tree classifiers.
The CNN is, maybe, the most generally received neural system sent in machine vision frameworks. A few reasons exist for this. To begin with, the CNN’s engineering is intended to copy all the more intently that of the human visual cortex and example acknowledgment instruments. This is conceivable in light of the fact that the CNN is separated into a few neuronal stages that perform distinctive functions.
In CNNs, convolutional layers are utilized to perform highlight extraction, similarly as convolution administrators are utilized to discover highlights, for example, edges. In ordinary picture handling, picture channels, for example, Gaussian obscuring and middle separating play out this errand. CNN structures, then again, imitate the human visual framework (HVS) where the retinal yield performs highlight extraction, for example, edge discovery. (Figure affability of Massachusetts Institute of Technology).
In this improved figure, both the convolutional and pooling layers are demonstrated independently for illustrative purposes. By and by, they structure some portion of the total CNN. In CNNs, convolutional layers are utilized to perform include extraction, similarly as convolution administrators are utilized to discover highlights such edges.
In regular picture preparing, picture channels, for example, Gaussian obscuring and middle separating can be offloaded to field-programmable entryway clusters (FPGA) to perform this task.
Imitating the cerebrum
Similarly as various classifiers can be utilized to recognize questions inside pictures, various kinds of neural systems exist that can be conveyed to perform picture grouping capacities. Such neural systems endeavour to copy organic neural systems utilized in the human visual framework and mind
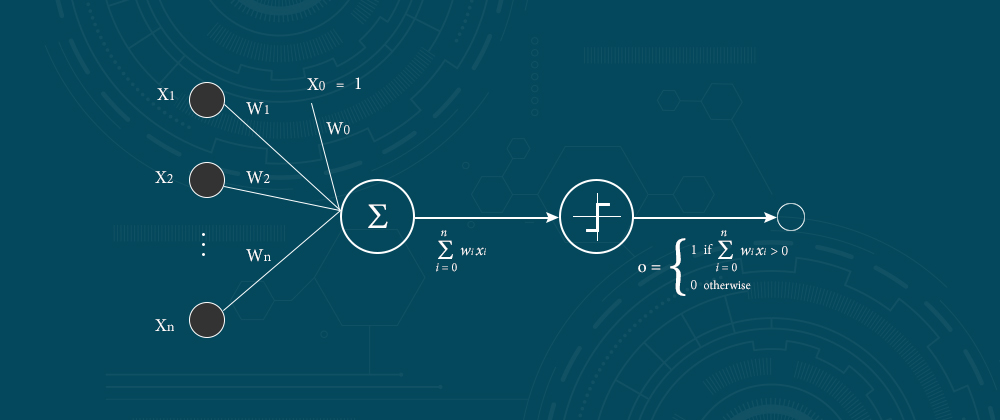
Invented in 1957 by Frank Rosenblatt, the Perceptron models the neurons in the cerebrum by taking a lot of paired information sources, duplicating each by a persistent esteemed weight and thresholding the aggregate of these weighted data sources imitating natural neurons (Figure cordiality of Andrey Kurenkov).
The Perceptron models the neurons in the mind by taking a lot of double information sources (close by neurons), increasing each contribution by a ceaseless esteemed weight (the neurotransmitter solidarity to each close by neuron), and thresholding the total of these weighted contributions to yield a “1” if the whole is sufficiently large and generally a “0” likewise that organic neurons either fire or not (see “A ‘Brief’ History of Neural Nets and Deep Learning,” by AndreyKurenkov.
Deep Learning and Machine Vision have quite a few major noteworthy differences and depending on the activity that needs to be performed one can pick the perfect choice accordingly.
Conclusion
Understanding those distinctions will be fundamental for any organization setting out on an industrial facility mechanization venture. Since those distinctions are critical to deciding when it bodes well to use either in a processing plant mechanization application.
Customary principle based machine vision is a viable instrument for explicit employment types. Also, for those circumstances that need human-like vision with the speed and unwavering quality of a PC, deep learning will demonstrate to be a genuinely game-evolving choice.
